
Introduction
If you're interested in collaborating with other developers, contributing to open source, or becoming a professional programmer, learning Git is essential. Git is one of the most popular version control systems used by millions of developers worldwide. If you are planning to start contributing to open-source or work in a company with collaborative development, having a solid understanding of Git will greatly benefit you.
Knowing Git proficiently will give you the ability to work on large-scale projects, reduce error rates during collaboration, and improve the overall efficiency of the development process. Plus, you'll feel a lot more confident when creating a Pull Request on GitHub or GitLab.
Of course, like with many tools in the programming world, Git is not the only version control system available. There are also tools called Mercurial and Subversion, but Git has gained widespread popularity due to its speed, flexibility, and powerful features like branching and merging.
In our days, developers are not using Mercurial as much as they used to, and Git has become the standard for version control in the industry. So, to answer your question of which version control system to learn, Git is the way to go.
But, if all the Git commands you know are "git add" and "git status", you are at the right place because this series of articles will take you from beginner to advanced, covering all the main features of Git in a step-by-step manner.
You can do a lot of things with git, and many of the rules of what you *should* do are not so many technical limitations, but are about what works well when working together with other people. So git is a very powerful set of tools.
Linux Torvalds (Creator of Git and Linux)

This article is only part 1 of the whole series and will cover the basics of Git, including installation, creating a repository, and working with commits.
Let's talk about what to expect from this guide in more detail and how it will help you become a proficient Git user for collaboration.
This Guide will Cover
The purpose of this guide is to provide you with a step-by-step understanding of Git and its basics and how it can be used for version control.
Every command that I will run throughout this article will be executed on my machine. Plus, I will attach a screenshot of each command's output to give you a visual representation of what to expect when using Git.
Note. There are different programs with user-interface to use Git, such as GitHub Desktop, SourceTree, and GitKraken. However, in this guide, we will focus on using Git through the command line for a more in-depth understanding of Git's functionality.
This article has many screenshots, tips, and useful examples to ensure that you clearly understand each concept and operation.
This guide will cover the following topics:
- Short history of Git and why it was created.
- Installing Git on Mac, Windows, and Linux.
- Learning Git workflow. How developers use Git to manage their code and collaborate with others.
- Staging changes and creating Git commits.
- Watching code diff and managing commit history.
- Splitting changes into smaller commits.
There's a lot to cover here, but you can skip sections if you already know about specific Git features. But, if you are new to Git, I recommend going through the guide step-by-step to ensure a comprehensive understanding.
To start talking about Git, it's important to understand the reason it was created. It would be challenging to effectively utilize Git without fully understanding its purpose and origin.
The Genesis of Git
Git was created by a well-respected man in the programming world, Linus Torvalds, in 2005 as a version control system for the development of the Linux kernel. The main issue that Linus had at that time when working on the Linux kernel was to accept contributions from multiple developers without the risk of code conflicts and loss of work.

Imagine you start working on an open-source project and people start helping you by sending code changes via email. That's what Linus Torvalds was facing, and it became quite challenging to merge all those different versions of code efficiently.
Git was born out of the need to efficiently manage and collaborate on software development projects. But you can also work by yourself and use Git as a way to track changes and easily revert to previous versions if needed.
You don't even need an internet connection for most Git operations. It works locally on your computer, allowing you to track changes and make commits without needing to be connected to a remote repository. Let's see how Git can be installed.
Installing Git on your computer
Installing Git on your computer is a straightforward process. Depending on your operating system, there are different methods to install Git. But, before you do that, double-check that you don't already have Git installed on your system.
On Mac and Linux, open the Terminal; on Windows, open the command prompt or Git Bash and type the following command to check the Git version:
git --versionOn my Mac, it gives this output:
git version 2.39.3 (Apple Git-145)If you don't have Git installed, you'll get a message that the command is not found. Please refer to the official Git documentation or the appropriate installation guide for your operating system to install Git on your computer.
After the installation, check the git --version command again, and you should see the version number displayed, confirming that Git has been successfully installed on your computer. Let's see what the everyday Git workflow looks like and how you can start using it for your projects.
The Git Workflow
The Git workflow involves a series of steps to track changes and collaborate on a software project. Your workflow might include the following steps:
- When you start a new project, you initiate a new Git repository. The repository is a storage space where Git tracks all the changes and commits made to your project.
- When you write a new piece of code, you add and commit changes to the Git repository with a specific message that describes the changes made.
- When you modify code that is already in the Git repository, you make changes and then add and commit those changes as well. It's like writing a history of your code, for example, when you wrote a function that converts temperature from Fahrenheit to Celsius, you can make a commit with the message "Added Fahrenheit to Celsius conversion function".
- When you would like to collaborate with other developers on a project, you can use Git to push your changes to a remote repository. There are several hosting services available, such as GitHub, Bitbucket and GitLab, that allow you to create a remote repository and share your code with others.
- When you want to split your work with other developers or work on different software versions simultaneously, you can create branches in Git. Branching allows you to create a separate context within the repository where you can make changes without affecting the main codebase.
- When you're fully ready to merge your changes back into the main codebase, you can create a pull request. This pull request serves as a way for other developers to review your changes and decide whether to incorporate them into the main codebase.
- Once your changes have been reviewed and approved by other developers (if you work in a team), you can merge them into the main codebase. Git not only allows for efficient collaboration among developers, but also provides a structured and organized workflow that tracks changes, facilitates code reviews, and ensures the integrity of the project.
Your Git workflow might slightly differ depending on the specific needs and requirements of your project and team. But the goal remains the same: to track changes, collaborate with other developers, and ensure the integrity of the project through an organized and efficient workflow using the Git version control system.
Initialize Git Repository
When you have Git installed on your machine, it is simple to create a new repository. You just use your terminal or command line to navigate to a directory where you want to start tracking your code, and then use the command git init to initialize a new Git repository. It will say something like:
Initialized empty Git repository in /Users/name/my-project/.gitCongratulations, you have successfully created a new Git repository! To check the current status of your Git repository, you can use the command git status. In my case, it says:

When you initialize a new repository in Git, it creates a "master" branch by default. This branch is where the main codebase resides. The first line will always tell you on which branch you are currently working when you run git status in your terminal window. We'll talk more about branches in the third part of this series.
The next line says that you don't have any commits yet. It means that you haven't made any changes to the code that are being tracked by Git.
The last line lets you know that there are no files modified or added to be tracked by Git.
Tip. To remove a Git repository from the project, run the command rm -rf .git in the root of your project. Once you delete it, it cannot be undone.
Git Commits
Let's imagine that your boss gives you an assignment, to write a JavaScript function that returns the sum of two numbers.
I'm going to create an empty "index.js" file in the directory where Git was initialized. If I run the command "ls" which will list directory contents, I'll see that the "index.js" file has been created.

Note. Just if you are curious, why I have a (master*) written in my terminal prompt, how does my terminal know about Git in the first place. Firstly, it indicates that I am currently on the "master" branch in my Git repository. Secondly, Git is extremely popular among programmers and there are many tools that help us to work with git. In my case, I've installed a terminal framework for a ZSH shell that I'm currently using for my terminal. It's called "Oh My Zsh" and it provides different configuration for the terminal, including displaying the current branch in the prompt.
The most common Git command for programmers who use terminal to run is git status. As the name suggests, "git status" is used to check the current status of your Git repository. Basically, any changes to the project can be tracked and viewed using the git status command.
If we run git status now, it will indicate that there is an untracked file, "index.js":
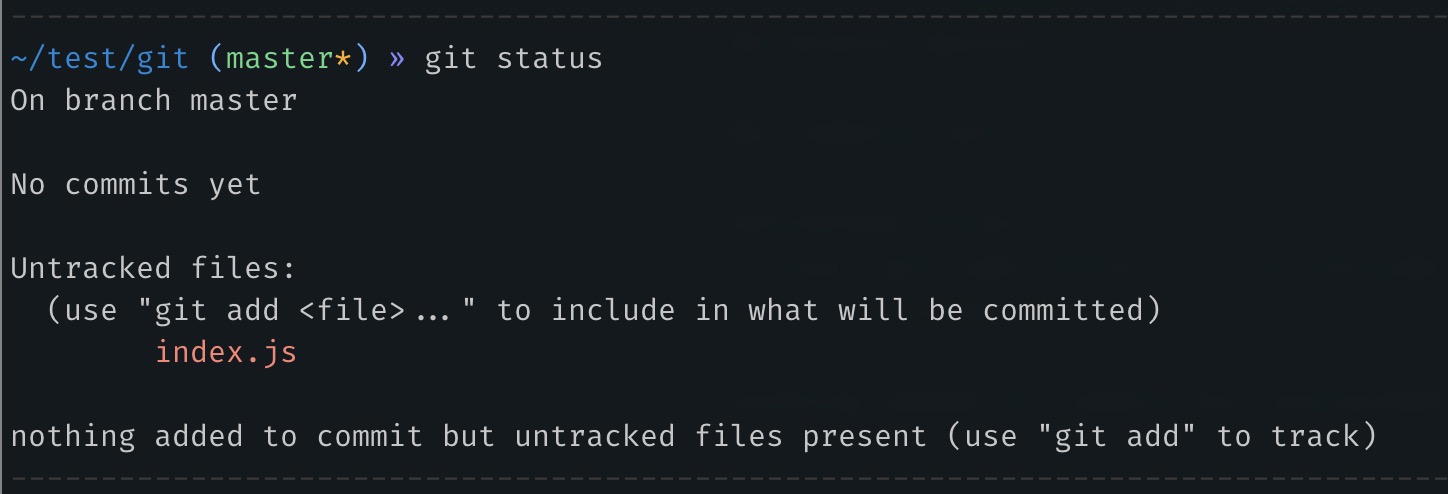
Untracked files are those files that have been created or modified but are not yet being tracked by Git. When Git tracks the file, it sees every single change made to the file, even if you remove a single trailing space, Git will know about it.
To track the file, we need to add it to the Git repository. But, we don't want it just now because the file is empty, and we haven't made any changes to it yet.
It would be better to add a function that we suppose to write in the "index.js" file before adding the file to Git. You can do the same to follow along with the article. This is what I'm going to write:
function add(x, y) {
return x + y;
}That's good! Running git status gives us the same output as previously:

It happens because previously Git was not aware of the existence of the "index.js" file, and now it is recognizing it as an untracked file as it did before.
We notice right away, at the end of the output, it says to use git add to track changes. Let's add the "index.js" file to the Git repository.
Stage Changes Before Commit
You might think, "Why do I need to stage changes before committing them?". Allow me to explain.
Staging changes allows us to review and organize the modifications we want to include in our next commit. If you have multiple changes across different files, staging them separately allows you to have more control over what will be included in each commit.
It's useful when you implement multiple code changes that are logically separate and want to keep them separate in your commit history. For example, you change the navigation bar color and also add a new button to the footer area. These 2 changes are logically separate, so it would be better to stage and commit them individually.
You would add navigation bar changes first, commit them with some message describing the change, and then add the button addition, committing it with its own descriptive message.

You can think of staging as packing your suitcase because you decide on what items to pack and what to leave behind. Each suitcase is like a commit, containing a specific set of changes that you are ready to save in your Git history.
Let's add the "index.js" file to staging by executing the "Add" command:
git add index.jsLet's see what has changed when we run git status now:
Note. When you're just starting to learn Git, it's important to run git status after making any changes or commands to see the current status of your repository. It will provide you with information about any untracked, modified, or staged files. But as you become more fluent with Git, you will develop a sense of when it's necessary to check the status and can skip this step in certain situations.

Running git status now shows that there is a new file called "index.js," which is currently ready to be committed.
It also shows the command git rm --cached <file> that you can use to unstage a file if you mistakenly added it, replacing "<file>" with the name of the file you want to unstage. Let's commit the changes.
Create your First Commit
Commits in Git are organized into a history of changes made to a repository over time. A good comparison will be playing a video game. Each time you make significant progress in the game, you save your progress. Similarly, when you make a commit in Git, which serves as a save point of your work.
This way, if something goes wrong in the future, you can easily revert to a previous commit and restore your work, like going back to a saved checkpoint in a video game.

Speaking in more professional language, when you make a commit, it will move files from a staging area to a new checkpoint in the history of your codebase. In our case, "index.js" is ready to be committed; it's in the staging area; let's go ahead and commit it.
To make a Git commit, we run the command "Commit" with the flag "-m", which stands for "message", like this:
git commit -m "Create index.js with 'add' function to calc the sum of two numbers"After "-m" we write a commit message in single or double quotes explaining the changes that were made in this commit. There are slight rules when most programmers use writing commit messages; some of them are:
- The commit message should not be longer than 72 characters. In the next section, we'll shortly talk about how to write long, multiline commit messages.
- We use short words to save characters. Instead of writing "calculate", we can write "calc", instead of "Created" we use "Create".
- Commit messages should be concise and descriptive, summarizing the changes made in the commit.
- We usually skip articles when writing commit messages, such as "a", "an", or "the" to save space and make the message more concise.
Note. Depending on the place you will be working, your rules might be different for writing commit messages. But these 3 rules are the most commonly followed.

When we executed the commit command, in the output of the command, you see how many files were changed and the number of insertions and deletions. In other words, new lines were added and existing lines removed.
Since we added 3 lines of code to "index.js", our commit shows 3 insertions.
If we run git status now, we'll see that there is nothing to commit and our working tree is clean.

"Working tree clean" means that there are no uncommitted changes in the repository. Not for long because our boss gives us the next assignment; we need to modify our function so that no one could use it to add 2 strings together.
With the current implementation, if we run add('hello ', 'world'), it will return "hello world", which is not what we want. One way to address this issue is by modifying the code to check the data type of the inputs and only perform addition if both inputs are numbers.
Let's now modify the "index.js" file and see the changes reflected in Git.
I'm going to just open the file and write, and before returning the result, I'm going to check for input types.
function add(x, y) {
if (typeof x !== 'number' || typeof y !== 'number') {
throw new Error('x and y must be numbers');
}
return x + y;
}Awesome! Plus, we are going to create a "readme.md" file to tell people how to use our "add" function. I'll create a "readme.md" with this content:
- `add(x, y)` function excepts only numbersIf we run git status now, we'll see what we expect:

The "index.js" is modified and "readme.md" is untracked since we didn't add it to the repository yet. We would rather not stage all the changes at the same time, since these changes are fundamentally different and require a different commit message. Let's use my favorite command:
git add -pThe "-p" flag in the Git Add command allows you, instead of adding all changes at once, to interactively choose which changes to stage for the next commit. It shows a diff of the changes and prompts to choose whether to stage each change or not.
It's like reviewing each change and deciding whether to include it in the commit. This is what it looks like in my terminal:

It shows me the change that I did to the "index.js" file and asks me if I want to stage this hunk of changes. You need to type one of the suggested letters to tell Git whether you want to stage this hunk or not.
Here is the list of all available commands for "git all -p":
- y - Stage this hunk.
- n - Do not stage this hunk.
- q - Quit; do not stage this hunk or any of the remaining ones.
- a - Stage this hunk and all later hunks in the file.
- d - Do not stage this hunk or any of the later hunks in the file.
- e - Manually edit the current hunk.
- ? - Print help.
- g - Select a hunk to go to.
- / - Search for a hunk matching the given regex.
- K - Leave this hunk undecided; see previous hunk.
- s - Split the current hunk into smaller hunks.
I'm going to stage this hunk and type "y" and press "Enter". Since Git is not tracking the "readme.md" file, it will not be included in the interactive staging process. But that's fine because we can add it separately using the command git add readme.md later.
Tip. If you want to add all the changes to the staging phase, you can run git add -A or git add --all to add all modified and untracked files at once. It's easier than adding each file individually with the git add <file> command.
Now, since we added changes from the "index.js" file to staging, our Git status should tell us that we have added changes ready to be committed in "index.js", and an untracked file "readme.md". Let's double-check it to make sure we are right.
git status
Yep! The "index.js" is painted in green, and the "readme.md" is painted in red. Which means that one file is now staged for commit and the other is still untracked.
Let's create a second commit:
git commit -m "Add validation to user input in index.js file"Congratulations! You've successfully created a second commit; it's not as hard as it may seem. Let's keep moving and do the last commit for the "readme.md" file. But first, we need to add it to the staging. I'm going to do that with this command:
git add -AWhich will add all the changes, including unstage and untracked files.

Now, Git sees the "readme.md" and tells us that this file is staged and ready to be committed.
git commit -m "Update readme.md file with project instructions and description"Hit "Enter", and we are done with 3 commits in our repository! Let's now see how to deal with long commit messages.
Create a Multiline Commit Message
As we know by now, you should only write commits that are 72 characters long or less for better readability. It's not a strict requirement, but a good practice to follow. If your commit message exceeds 72 characters, it will just be split into multiple lines when displayed.
There are multiple ways to write multiline commit messages in Git. One of them is to chain the "-m" flag with multiple commit messages like this:
git commit -m "Add a func that creates new user in DB" -m "Also add validation to prevent registration issues"Your final commit message will look something like this:
Add a func that creates new user in DB
Also add validation to prevent registration issuesThe second way is my favorite because it allows for more readability and organization within the commit message. Plus, I love using the Vim editor to compose my commit messages instead of chaining multiple "-m" flags.
It doesn't matter whether your default terminal editor is; you can create a multiline commit message by simply typing `git commit` without the `-m` flag. For example:
git commitSince I'm using Vim, I've met with this screen:

The first line is where you write your commit message. You can easily see the line limit here because your message will break into a separate line if it exceeds the set character limit.
As you can see in the next screenshot, I was writing, "This is a very long message here! I keep writing it and writing until it breaks into a separate line" message, and it shows the commit message exceeds 72 characters by highlighting with the red color.

To fix this, I just need to separate lines with a space like this:

Now, I can exit Vim. To save changes and exit Vim, hold the "Shift" key and press the "Z" key twice. Shirt + Z Z. Let's learn about the "git diff" command now.
The Git Diff command
We've modified the "index.js" file and created a "readme.md" file, and now we are ready to learn about the "Diff" command. The "Diff" command shows the differences between different versions of files in your Git repository.
But if we run it right now, we will not see anything because we haven't made any new changes since our last commit. To fix it, let's introduce some changes to both our files.
Your boss comes to you and gives you another task: write a function that returns the difference between two given numbers. Let's add the function to our "index.js" file:
function add(x, y) {
if (typeof x !== 'number' || typeof y !== 'number') {
throw new Error('x and y must be numbers!');
}
return x + y;
}
function diff(x, y) {
if (typeof x !== 'number' || typeof y !== 'number') {
throw new Error('x and y must be numbers!');
}
return x - y;
}Our boss also wanted to add an exclamation mark to the error message in the "index.js" file, so we did that as well. We also want to add an instruction to the "readme.md" file about how to use the "diff" function.
- `add(x, y)` function excepts only numbers
- `diff(x, y)` return the difference of 2 given numbersThere you go, we've made 2 changes since the last commit. There are no untracked files, since we haven't created anything new. Our git status should probably show us that we modified 2 files. Let's check this:
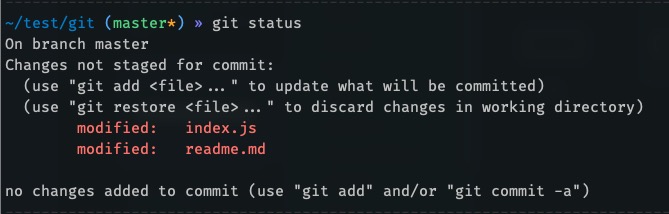
Yep! This is accurately what we expected. What if we want to see the changes that we've made to those 2 files in more detail? This is where the "Diff" command is helpful. Let's run it:
git diff HEADTip. In the context of Git, HEAD means the most recent commit in the current branch. With git diff HEAD we tell Git to show the differences between the current state of the files and the most recent commit in the branch.
This is what the output looks like:
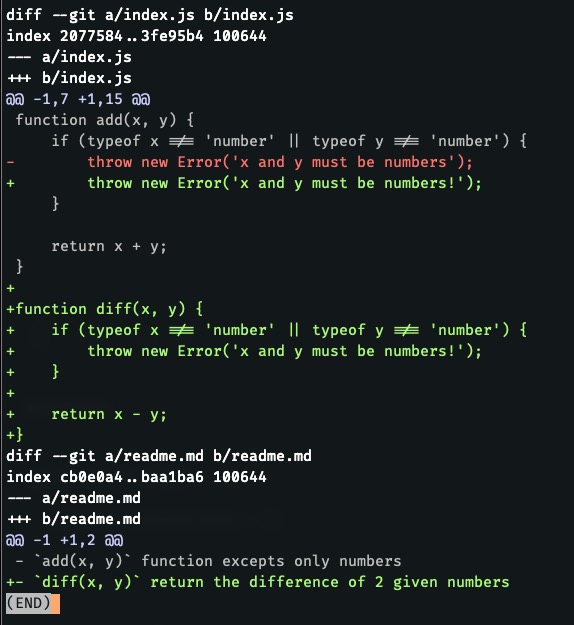
We clearly see that the diff is split into 2 files - "index.js" and "readme.md". The "+" symbol indicates that we added a line, and "-" indicates that we removed a line from the file.
Note. It might look strange at first as why we have "+-" in "readme.md", but the "-" symbols is just a dash that we use in Markdown and not the hyphen used in the diff output.
Tip. If you have many changes, and they do not fit in your terminal, you can use the "j" and "k" keys to scroll up and down within the git diff output. Where "j" is to move down and the "k" key is to move up. It often happens when you have a small terminal window. To exit, you can use the "q" key.
One useful flag with the "diff" command that you can use is the "--stat" flag. It's mostly used when we want to get a summary of the changes without seeing the actual differences.
git diff HEAD --stat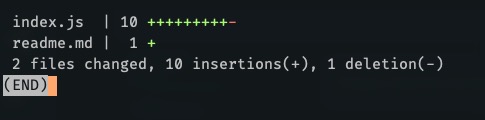
The output is very compact and provides a summary of the changes made in each file. In our example, the line that we modified in the "index.js" file is considered to be removed and added a new one instead. If me modify at least one character on the line, the entire line is considered to be replaced with a different one.
If you want to see the difference between the current state of a file and the last commit in a branch, you should use the "diff" command.
For example, you introduced some changes to your code and went to make a cup of coffee. When you come back, you can use the git diff HEAD command to quickly see what changes you made in your absence to quickly jump back into your code and continue working.
The "git diff" command can do even more than just comparing the current state of files with the most recent commit, but we will talk about that later when we learn about Git branches. But before that, we need to know about one simple command, it's called the "Git Log".
The Git Log command
As we saw with the "Diff" command, Git has many built-in commands and features that help with controlling different versions of your project. This is why it's called VCS, The Version Control System. Its purpose is to keep track of your changes and provide a chronological history of commits made in your project.
The "Git Log" command was made specifically for that, to show you a chronological history of commits made in your project.
Even though it's called "Git Log", you can think of it as a "Git History" because that's precisely what it does. It shows us a chronological list of all the commits that have been made in the repository. Let's run it in our project.
git logIt shows us that we have 3 commits in our Git history on the master branch.
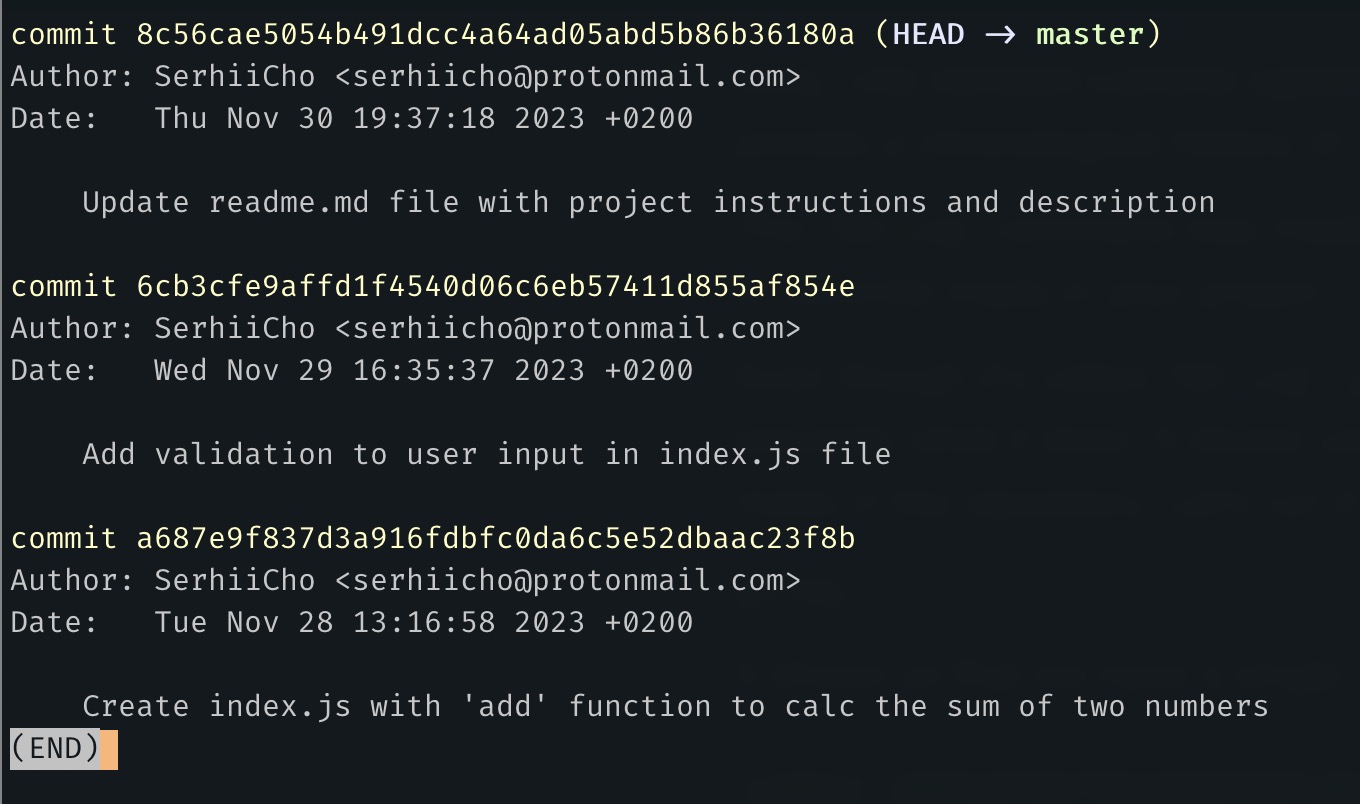
These long strings like "a687e9f837d3a916fdbfc0da6c5e52dbaac23f8b" are commit hashes, basically they are like unique identifiers for specific commits. In your example, they will be different, as each commit has a different hash.
Note. For "git log" output, you can use the same navigation keys as for "git diff HEAD". "j" to move down, "k" to move up, and "q" to exit.
The author and date fields are straightforward, displaying the author of the commit and the date it was made. The older the commit, the lower it appears in the git log. As you can see, I've made them on different days to better show you how the chronological order works.
Note. If you want to change the Git name and email associated with your commits, you can use the git config command to update your user information. To set the name, run git config --global user.name "<your name>", and to set the email, run git config --global user.email "<your email>". Since you added the flag "--global", you will set the name and email globally for all your Git repositories on your machine, instead of manually changing them for each repository.
Splitting Changes into Smaller Commits
The last line in the commit is the commit message itself that we gave when we made the commit. Since we currently have staged changes that are ready to be committed, let's run the "Commit" command to create new commits. Let's see the git status result, to refresh our memory again.
We are at the point where we've modified 2 files, but we haven't staged those changes. It's clear from our git status output. Let's do it with my favorite command git add -p and stage only changes where we modified the add function by adding the "!" to the end of the error message.
After running git add -p you will see something like this:
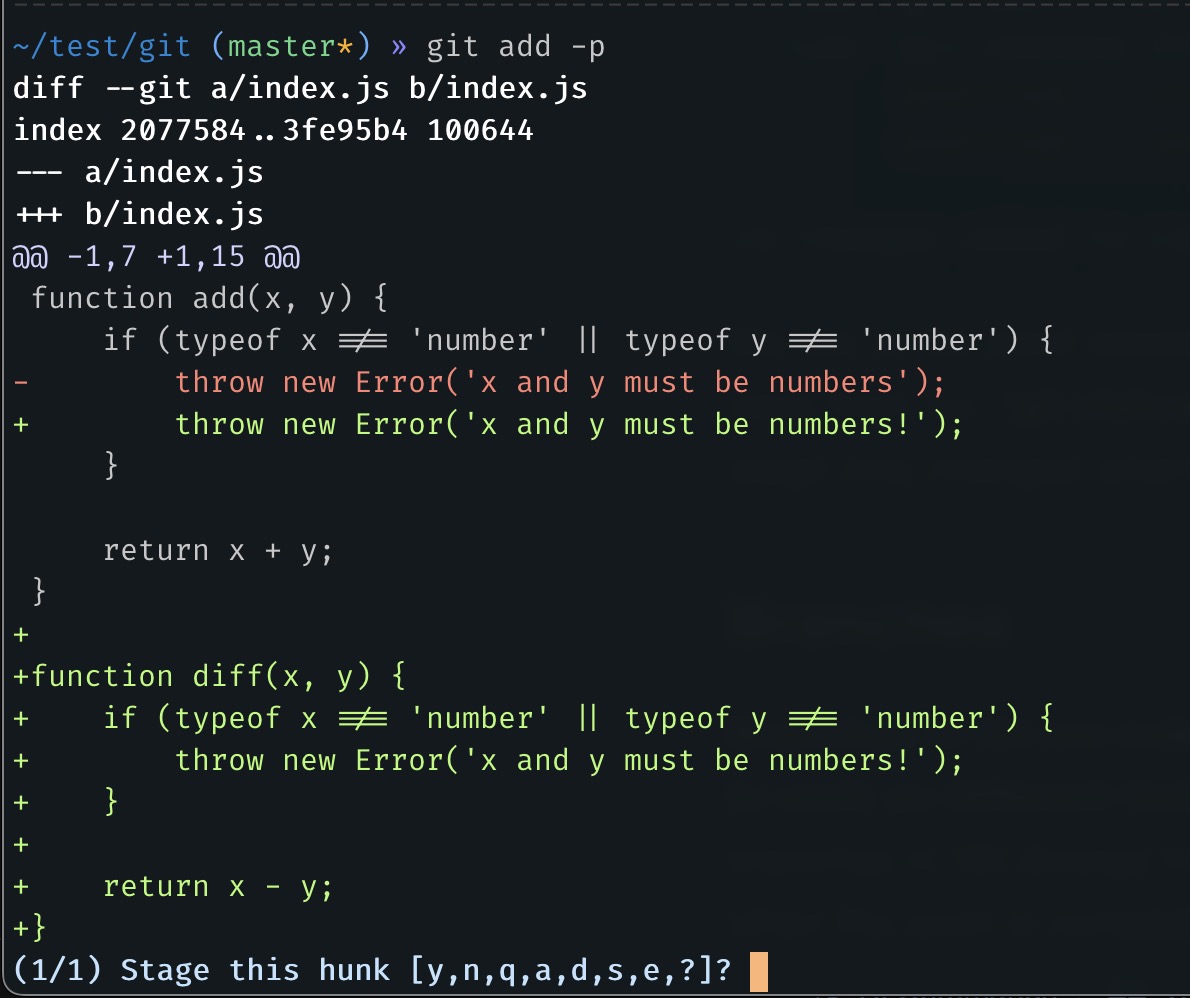
From this output, we can see the problem. Git shows us the changes in the whole "index.js" file instead of just the specific change we made. What if I want to make a separate commit for modifying the line and a separate commit for a "diff" function.
What if I tell you that we can do that? Press "s", which stands for "split", and hit the "Enter" key.

Git says, "Split into 2 hunks", which is precisely what we see. It split the changes in the "index.js" file into 2 separate hunks. Let's stage this change with "y", and for 2 other changes we will choose "n" to skip staging them for now.
Tip. Remember, if you want to know what are those letters mean at the bottom of the git diff -p output, just press "?" and hit the "Enter".
Even if we check the git status we will see that we modified the "index.js" file and some changes in this file are still not staged since we chose to skip staging them in the previous step.
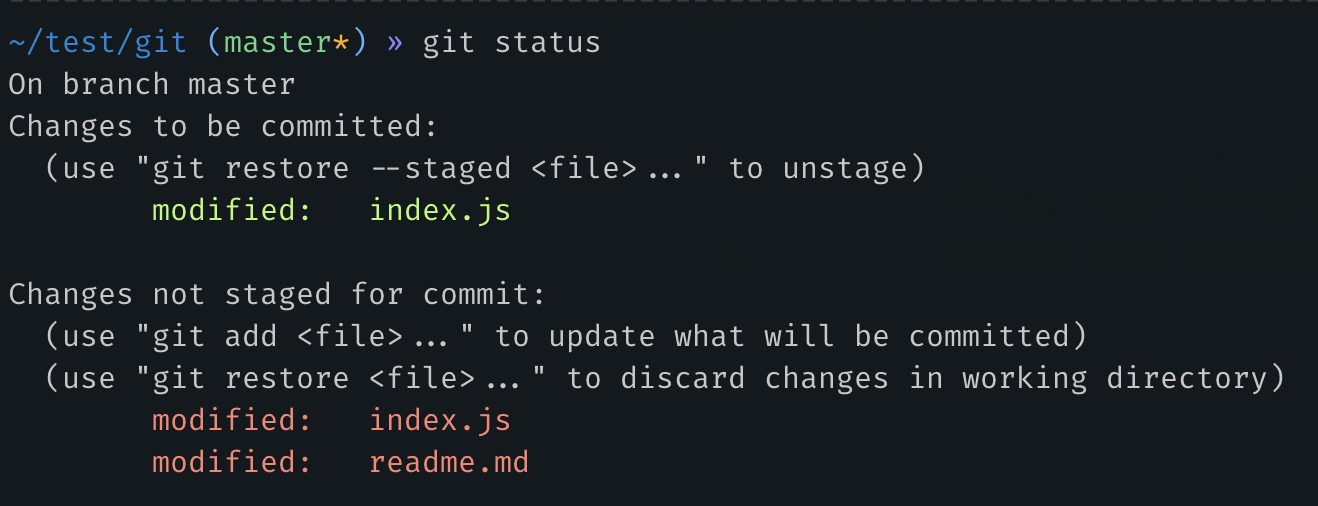
Let's commit these changes with a meaningful commit message.
git commit -m "Add '!' symbol to error message in 'add' func"Awesome! Let's run git diff HEAD to refresh our memory and to see the changes.

Yep! This is precisely what we expected to see after splitting changes in the "index.js" file. Now, we can either run git add index.js or use git add -p again to stage the remaining changes and create separate commits for each change. I'll run the first one.
git add index.js && git commit -m "Add 'diff' function to the index.js file"We've combined 2 git commands with double ampersands "&&" to stage the remaining changes in the "index.js" file and create a commit. The only thing that's left is to commit the changes in the "readme.md" file that we modified.
git commit -am "Add documentation for our 'diff' func"Tip. The flag "-am" in the Git commit command stands for "all" and "message". Using the "-am" flag in the Git commit command allows you to stage and commit all "tracked" changes with a single command, including providing a commit message. If you have only a few changes and want to skip the staging step, you can use the "-a" flag instead of "-am." Note that "tracked" changes are changes that have been previously added to the staging area. Created files or untracked files will not be included in the commit with the "-am" flag.
Git Status shows us that there is nothing to commit in our repository, since we have successfully staged and committed all the changes in both the "index.js" and "readme.md" files. Great job!
You can now run the git log command to see all the commits we have, and use the "j" and "k" keys to navigate up and down if they don't fit in your terminal window.
Undoing Commits in Git
Undoing commits in Git can be done in many ways, depending on whether you have pushed the commits to a remote repository or not. It's a more advanced topic and beyond the scope of this guide.
However, I've decided to write a separate, short article that will cover everything about undoing Git commits. Check it out after you read the conclusion. "Part 2. Undoing Commits".
Conclusion
Congratulations! You've reached the end of this guide on using Git for staging and committing changes. We've learned some of the most important commands and techniques for managing our repository's history.
Understanding how to split, stage, and commit changes in Git is an essential skill for effective version control. By following the best commit practices and focusing on the atomicity of commits, developers can ensure that each commit represents a meaningful and coherent set of changes.
The ability to explore the history of commits and their differences using commands like "git log" and "git diff" provides valuable insights into the development process.
However, we've just scratched the surface of what Git can do. This is just the first article in a series, "Git from Beginner to Advance".
The Part 2. Undoing Commits is already out and covers everything you need to know about undoing Git commits properly and without consequences.
The Part 3. Understanding Branching is already out. We will dive deeper into advanced Git concepts such as branching, merging, and more advanced workflows.
If you don't want to miss the future articles of this series, make sure to stay tuned or subscribe to specific topics, and we will notify you when the next article is out. If you need any clarification or suggestions, the comment section below is waiting for you to share your thoughts and engage in discussions.
Keywords: github, bitbucket, open-source, torvalds, commit, stageThe only way to do great work is to love what you do
Steve Jobs

